
About Me
I am a PhD candidate at the Computer Vision Lab at ETH Zurich, co-supervised by Prof. Luc Van Gool and Prof. Bernt Schiele. As a member of the Max Planck ETH Center for Learning Systems, I recently visited the Computer Vision and Machine Learning Department at the Max Planck Institute for Informatics, working with Prof. Bernt Schiele. Currently, I am a student researcher at Google, contributing to Federico Tombari's team. My research focuses on advancing multiple object tracking methods that can learn end-to-end from long video sequences, adapt dynamically, and leverages limited annotations in a self-supervised fashion. Additionally, I have worked on foundation models for object tracking and depth estimation. In the past, I explored fundamental challenges in deep learning, including domain generalization and uncertainty estimation.
News
- [2024/07] 2 papers accepted at ECCV 2024 (Walker and SLAck).
- [2024/06] Started working as a student researcher in Federico Tombari's team at Google.
- [2024/02] 3 papers accepted at CVPR 2024 (MASA, UniDepth, and KYN).
- [2023/09] Presenting our test-time adaptive tracker DARTH at ICCV 2023.
- [2023/09] Hosting the 1st Workshop on Visual Continual Learning at ICCV 2023.
Publications
Visit my Google Scholar profile for more publications.
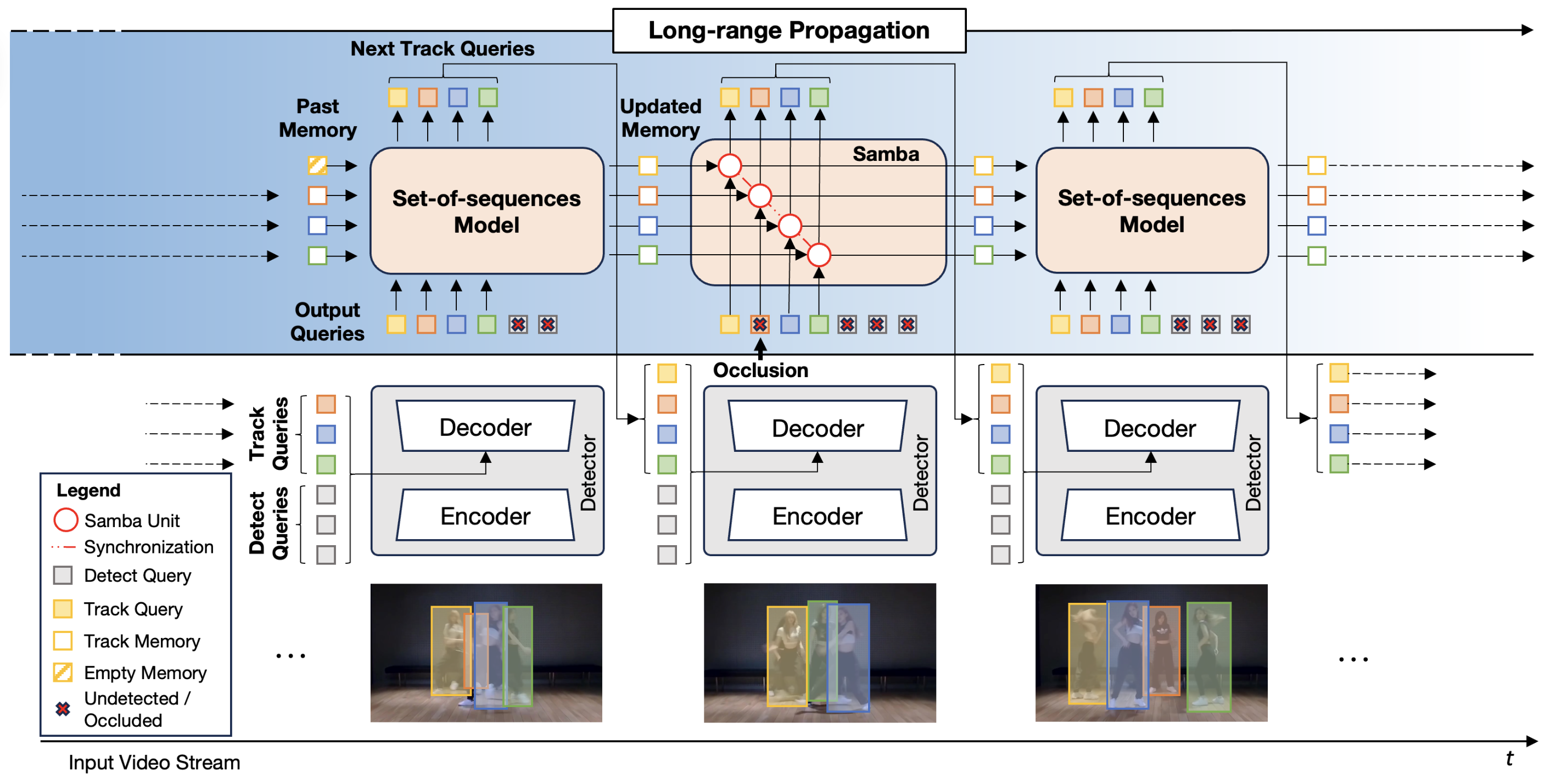 | Samba: Synchronized Set-of-Sequences Modeling for Multiple Object Tracking |
| Mattia Segu, Luigi Piccinelli, Siyuan Li, Yung-Hsu Yang, Bernt Schiele, Luc Van Gool | |
| arXiv preprint, 2024 | |
| Multiple object tracking in complex scenarios - such as coordinated dance performances, team sports, or dynamic animal groups - presents unique challenges. In these settings, objects frequently move in coordinated patterns, occlude each other, and exhibit long-term dependencies in their trajectories. However, it remains a key open research question on how to model long-range dependencies within tracklets, interdependencies among tracklets, and the associated temporal occlusions. To this end, we introduce Samba, a novel linear-time set-of-sequences model designed to jointly process multiple tracklets by synchronizing the multiple selective state-spaces used to model each tracklet. Samba autoregressively predicts the future track query for each sequence while maintaining synchronized long-term memory representations across tracklets. By integrating Samba into a tracking-by-propagation framework, we propose SambaMOTR, the first tracker effectively addressing the aforementioned issues, including long-range dependencies, tracklet interdependencies, and temporal occlusions. Additionally, we introduce an effective technique for dealing with uncertain observations (MaskObs) and an efficient training recipe to scale SambaMOTR to longer sequences. By modeling long-range dependencies and interactions among tracked objects, SambaMOTR implicitly learns to track objects accurately through occlusions without any hand-crafted heuristics. Our approach significantly surpasses prior state-of-the-art on the DanceTrack, BFT, and SportsMOT datasets. | |
| [arXiv] [Project Page] | |
 | Walker: Self-supervised Multiple Object Tracking by Walking on Temporal Appearance Graphs |
| Mattia Segu, Luigi Piccinelli, Siyuan Li, Luc Van Gool, Fisher Yu, Bernt Schiele | |
| European Conference on Computer Vision (ECCV), 2024 | |
| The supervision of state-of-the-art multiple object tracking (MOT) methods requires enormous annotation efforts to provide bounding boxes for all frames of all videos, and instance IDs to associate them through time. To this end, we introduce Walker, the first self-supervised tracker that learns from videos with sparse bounding box annotations, and no tracking labels. First, we design a quasi-dense temporal object appearance graph, and propose a novel multi-positive contrastive objective to optimize random walks on the graph and learn instance similarities. Then, we introduce an algorithm to enforce mutually-exclusive connective properties across instances in the graph, optimizing the learned topology for MOT. At inference time, we propose to associate detected instances to tracklets based on the max-likelihood transition state under motion-constrained bi-directional walks. Walker is the first self-supervised tracker to achieve competitive performance on MOT17, DanceTrack, and BDD100K. Remarkably, our proposal outperforms the previous self-supervised trackers even when drastically reducing the annotation requirements by up to 400x. | |
| [arXiv] [ECCV 2024 Paper] [Code] | |
 | SLAck: Semantic, Location, and Appearance Aware Open-Vocabulary Tracking |
| Siyuan Li, Lei Ke, Yung-Hsu Yang, Luigi Piccinelli, Mattia Segù, Martin Danelljan, Luc Van Gool | |
| European Conference on Computer Vision (ECCV), 2024 | |
| Open-vocabulary Multiple Object Tracking (MOT) aims to generalize trackers to novel categories not in the training set. Currently, the best-performing methods are mainly based on pure appearance matching. Due to the complexity of motion patterns in the large-vocabulary scenarios and unstable classification of the novel objects, the motion and semantics cues are either ignored or applied based on heuristics in the final matching steps by existing methods. In this paper, we present a unified framework SLAck that jointly considers semantics location, and appearance priors in the early steps of association and learns how to integrate all valuable information through a lightweight spatial and temporal object graph. Our method eliminates complex post-processing heuristics for fusing different cues and boosts the association performance significantly for large-scale open-vocabulary tracking. Without bells and whistles, we outperform previous state-of-the-art methods for novel classes tracking on the open-vocabulary MOT and TAO TETA benchmarks. | |
| [arXiv] [ECCV 2024 Paper] [Code] | |
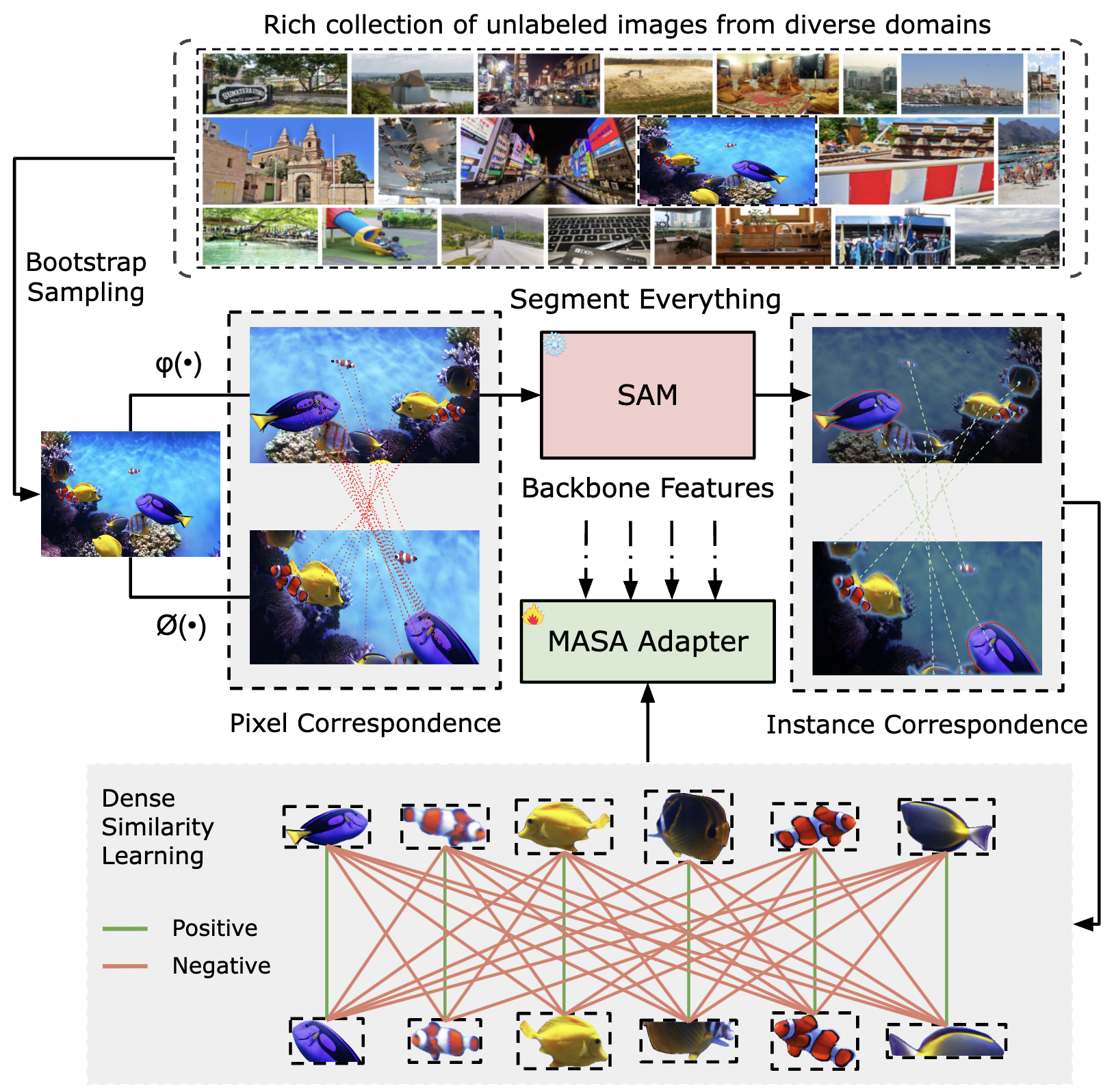 | Matching Anything by Segmenting Anything |
| Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu | |
| IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 | |
| The robust association of the same objects across video frames in complex scenes is crucial for many applications especially object tracking. Current methods predominantly rely on labeled domain-specific video datasets which limits cross-domain generalization of learned similarity embeddings. We propose MASA a novel method for robust instance association learning capable of matching any objects within videos across diverse domains without tracking labels. Leveraging the rich object segmentation from the Segment Anything Model (SAM) MASA learns instance-level correspondence through exhausive data transformations. We treat the SAM outputs as dense object region proposals and learn to match those regions from a vast image collection. We further design a universal MASA adapter which can work in tandem with foundational segmentation or detection models and enable them to track any detected objects. Those combinations present strong zero-shot tracking ability in complex domains. Extensive tests on multiple challenging MOT and MOTS benchmarks indicate that the proposed method using only unlabelled static images achieves even better performance than state-of-the-art methods trained with fully annotated in-domain video sequences in zero-shot association. | |
| [arXiv] [CVPR 2024 Paper] [Code] | |
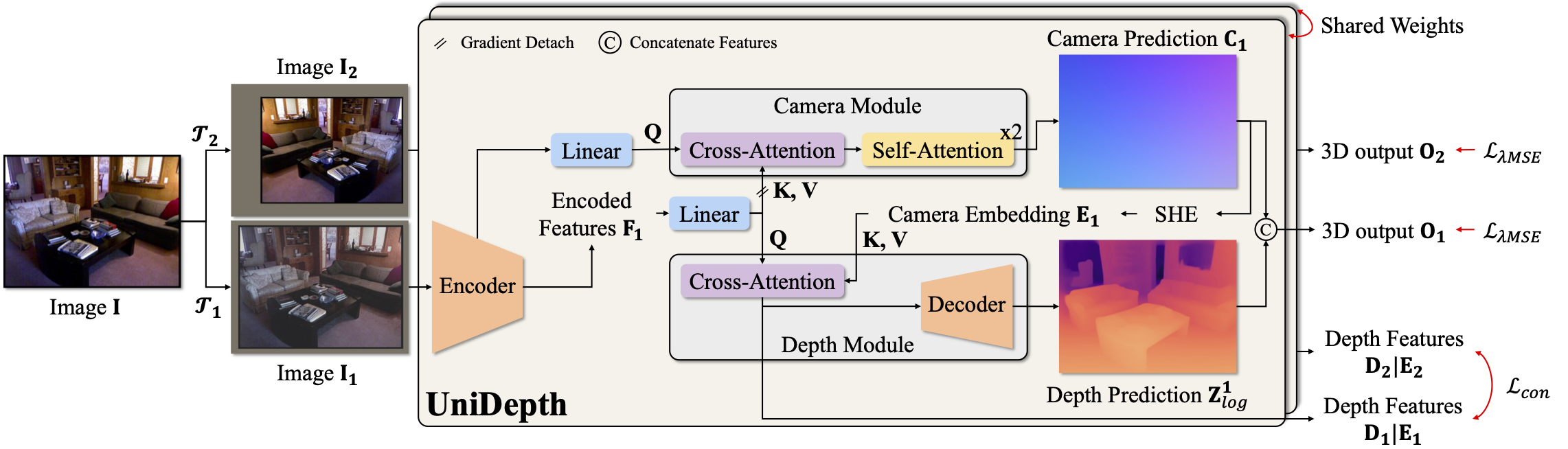 | UniDepth: Universal Monocular Metric Depth Estimation |
| Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, Fisher Yu | |
| IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 | |
| Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepth, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE methods, UniDepth directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepth implements a self-promptable camera module predicting dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. Thorough evaluations on ten datasets in a zero-shot regime consistently demonstrate the superior performance of UniDepth, even when compared with methods directly trained on the testing domains. | |
| [arXiv] [CVPR 2024 Paper] [Code] | |
 | Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning |
| Rui Li, Tobias Fischer, Mattia Segu, Marc Pollefeys, Luc Van Gool, Federico Tombari | |
| IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 | |
| Recovering the 3D scene geometry from a single view is a fundamental yet ill-posed problem in computer vision. While classical depth estimation methods infer only a 2.5 D scene representation limited to the image plane recent approaches based on radiance fields reconstruct a full 3D representation. However these methods still struggle with occluded regions since inferring geometry without visual observation requires (i) semantic knowledge of the surroundings and (ii) reasoning about spatial context. We propose KYN a novel method for single-view scene reconstruction that reasons about semantic and spatial context to predict each point's density. We introduce a vision-language modulation module to enrich point features with fine-grained semantic information. We aggregate point representations across the scene through a language-guided spatial attention mechanism to yield per-point density predictions aware of the 3D semantic context. We show that KYN improves 3D shape recovery compared to predicting density for each 3D point in isolation. We achieve state-of-the-art results in scene and object reconstruction on KITTI-360 and show improved zero-shot generalization compared to prior work. | |
| [arXiv] [CVPR 2024 Paper] [Project Page] | |
 | DARTH: Holistic Test-time Adaptation for Multiple Object Tracking |
| Mattia Segu, Bernt Schiele, Fisher Yu | |
| International Conference on Computer Vision (ICCV), 2023 | |
| Multiple object tracking (MOT) is a fundamental component of perception systems for autonomous driving, and its robustness to unseen conditions is a requirement to avoid life-critical failures. Despite the urge of safety in driving systems, no solution to the MOT adaptation problem to domain shift in test-time conditions has ever been proposed. However, the nature of a MOT system is manifold - requiring object detection and instance association - and adapting all its components is non-trivial. In this paper, we analyze the effect of domain shift on appearance-based trackers, and introduce DARTH, a holistic test-time adaptation framework for MOT. We propose a detection consistency formulation to adapt object detection in a self-supervised fashion, while adapting the instance appearance representations via our novel patch contrastive loss. We evaluate our method on a variety of domain shifts - including sim-to-real, outdoor-to-indoor, indoor-to-outdoor - and substantially improve the source model performance on all metrics. | |
| [arXiv] [ICCV 2023 Paper] [Code] | |
 | COOLer: Class-Incremental Learning for Appearance-Based Multiple Object Tracking |
| Zhizheng Liu*, Mattia Segu*, Fisher Yu | |
| 45th DAGM German Conference, DAGM GCPR 2023 (Oral) | |
| Continual learning allows a model to learn multiple tasks sequentially while retaining the old knowledge without the training data of the preceding tasks. This paper extends the scope of continual learning research to class-incremental learning for MOT, which is desirable to accommodate the continuously evolving needs of autonomous systems. Previous solutions for continual learning of object detectors do not address the data association stage of appearance-based trackers, leading to catastrophic forgetting of previous classes' re-identification features. We introduce COOLer, a COntrastive- and cOntinual-Learning-based tracker, which incrementally learns to track new categories while preserving past knowledge by training on a combination of currently available ground truth labels and pseudo-labels generated by the past tracker. To further exacerbate the disentanglement of instance representations, we introduce a novel contrastive class-incremental instance representation learning technique. Finally, we propose a practical evaluation protocol for continual learning for MOT and conduct experiments on the BDD100K and SHIFT datasets. Experimental results demonstrate that COOLer continually learns while effectively addressing catastrophic forgetting of both tracking and detection. | |
| [arXiv] [DAGM GCPR 2023 Paper] [Code] | |
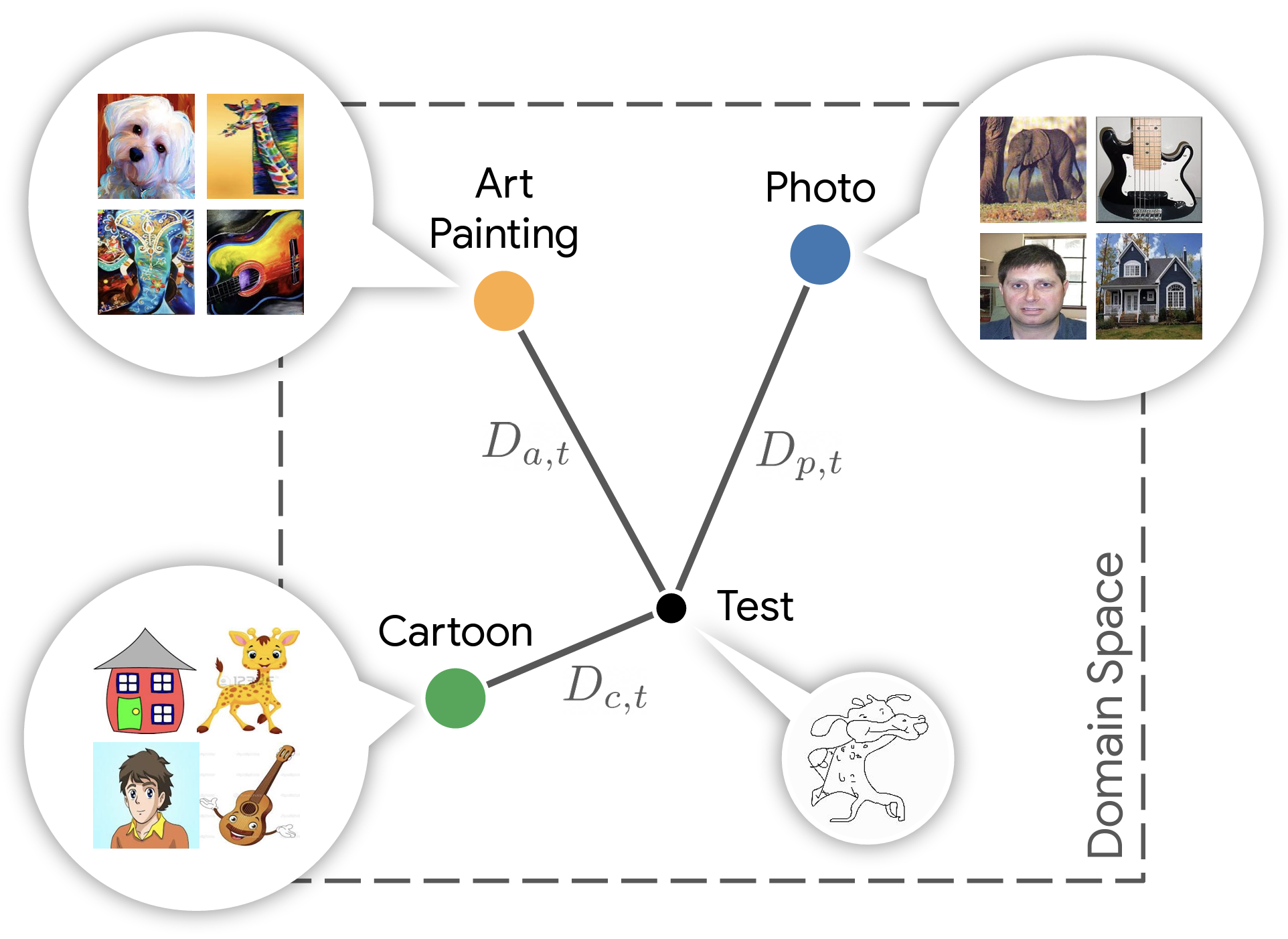 | Batch Normalization Embeddings for Deep Domain Generalization |
| Mattia Segu, Alessio Tonioni, Federico Tombari | |
| Pattern Recognition (PR), 2023 | |
| Domain generalization aims at training machine learning models to perform robustly across different and unseen domains. Several recent methods use multiple datasets to train models to extract domain-invariant features, hoping to generalize to unseen domains. Instead, first we explicitly train domain-dependant representations by using ad-hoc batch normalization layers to collect independent domain's statistics. Then, we propose to use these statistics to map domains in a shared latent space, where membership to a domain can be measured by means of a distance function. At test time, we project samples from an unknown domain into the same space and infer properties of their domain as a linear combination of the known ones. We apply the same mapping strategy at training and test time, learning both a latent representation and a powerful but lightweight ensemble model. We show a significant increase in classification accuracy over current state-of-the-art techniques on popular domain generalization benchmarks: PACS, Office-31 and Office-Caltech. | |
| [arXiv] [PR 2023 Paper] | |
 | SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation |
| Tao Sun*, Mattia Segu*, Janis Postels, Yuxuan Wang, Luc Van Gool, Bernt Schiele, Federico Tombari, Fisher Yu | |
| Conference on Computer Vision and Pattern Recognition (CVPR), 2022 | |
| Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous-driving systems. Existing image-and video-based driving datasets, however, fall short of capturing the mutable nature of the real world. In this paper, we introduce the largest synthetic dataset for autonomous driving, SHIFT. It presents discrete and continuous shifts in cloudiness, rain and fog intensity, time of day, and vehicle and pedestrian density. Featuring a comprehensive sensor suite and annotations for several mainstream perception tasks, SHIFT allows to investigate how a perception systems' performance degrades at increasing levels of domain shift, fostering the development of continuous adaptation strategies to mitigate this problem and assessing the robustness and generality of a model. | |
| [arXiv] [CVPR 2022 Paper] [Project] | |
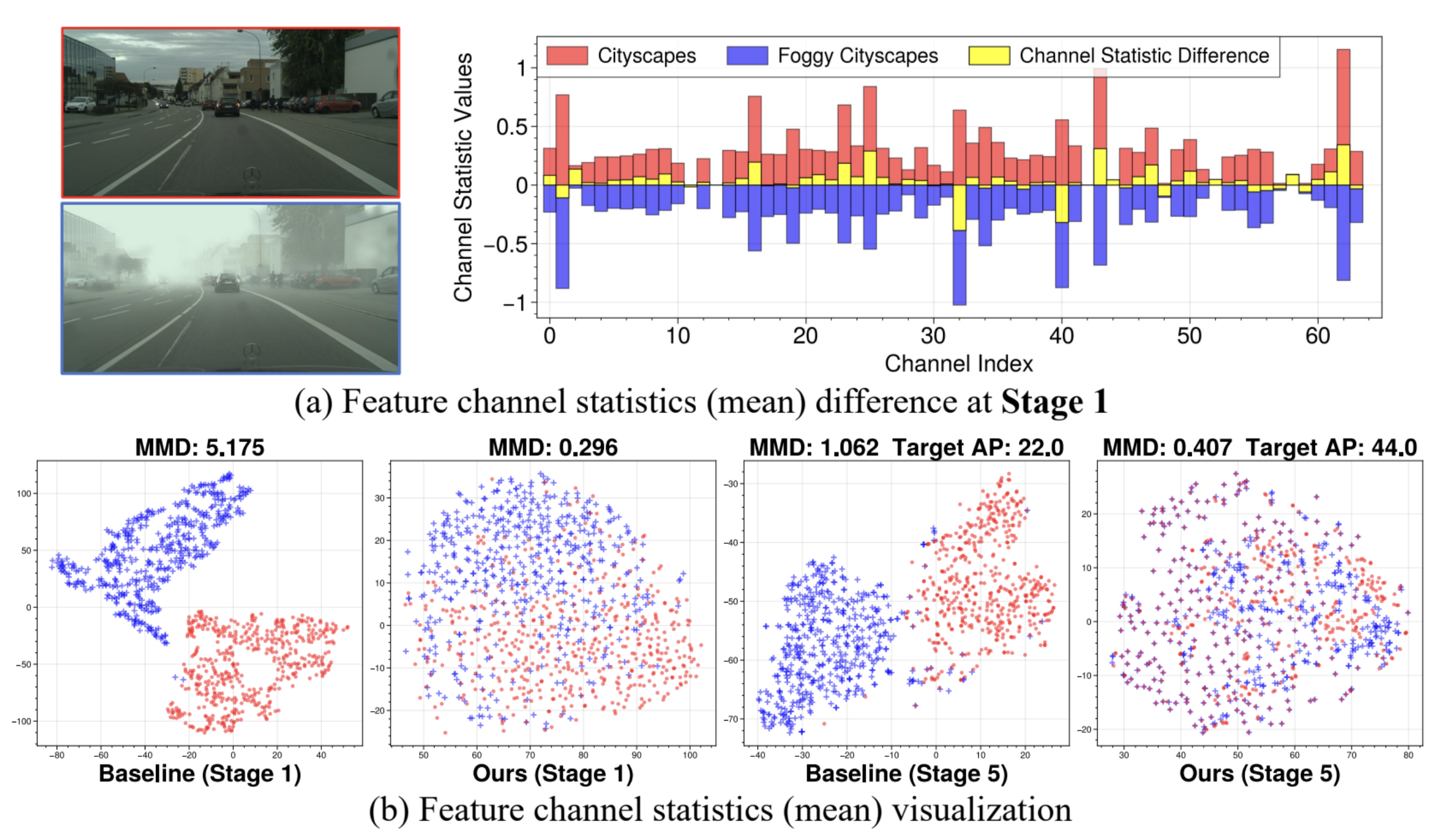 | Towards Robust Object Detection Invariant to Real-World Domain Shifts |
| Qi Fan, Mattia Segu, Yu-Wing Tai, Fisher Yu, Chi-Keung Tang, Bernt Schiele, Dengxin Dai | |
| International Conference on Learning Representations (ICLR), 2022 | |
| Safety-critical applications such as autonomous driving require robust object detection invariant to real-world domain shifts. Such shifts can be regarded as different domain styles, which can vary substantially due to environment changes and sensor noises, but deep models only know the training domain style. Such domain style gap impedes object detection generalization on diverse real-world domains. Existing classification domain generalization (DG) methods cannot effectively solve the robust object detection problem, because they either rely on multiple source domains with large style variance or destroy the content structures of the original images. In this paper, we analyze and investigate effective solutions to overcome domain style overfitting for robust object detection without the above shortcomings. Our method, dubbed as Normalization Perturbation (NP), perturbs the channel statistics of source domain low-level features to synthesize various latent styles, so that the trained deep model can perceive diverse potential domains and generalizes well even without observations of target domain data in training. This approach is motivated by the observation that feature channel statistics of the target domain images deviate around the source domain statistics. We further explore the style-sensitive channels for effective style synthesis. Normalization Perturbation only relies on a single source domain and is surprisingly simple and effective, contributing a practical solution by effectively adapting or generalizing classification DG methods to robust object detection. Extensive experiments demonstrate the effectiveness of our method for generalizing object detectors under real-world domain shifts. | |
| [arXiv] [Paper] | |
 | Normalization Perturbation: A Simple Domain Generalization Method for Real-World Domain Shifts |
| Qi Fan, Mattia Segu, Yu-Wing Tai, Fisher Yu, Chi-Keung Tang, Bernt Schiele, Dengxin Dai | |
| Pre-Print, 2022 | |
| Improving model's generalizability against domain shifts is crucial, especially for safety-critical applications such as autonomous driving. Real-world domain styles can vary substantially due to environment changes and sensor noises, but deep models only know the training domain style. Such domain style gap impedes model generalization on diverse real-world domains. Our proposed Normalization Perturbation (NP) can effectively overcome this domain style overfitting problem. We observe that this problem is mainly caused by the biased distribution of low-level features learned in shallow CNN layers. Thus, we propose to perturb the channel statistics of source domain features to synthesize various latent styles, so that the trained deep model can perceive diverse potential domains and generalizes well even without observations of target domain data in training. We further explore the style-sensitive channels for effective style synthesis. Normalization Perturbation only relies on a single source domain and is surprisingly effective and extremely easy to implement. Extensive experiments verify the effectiveness of our method for generalizing models under real-world domain shifts. | |
| [ICCV 2023 Paper] | |
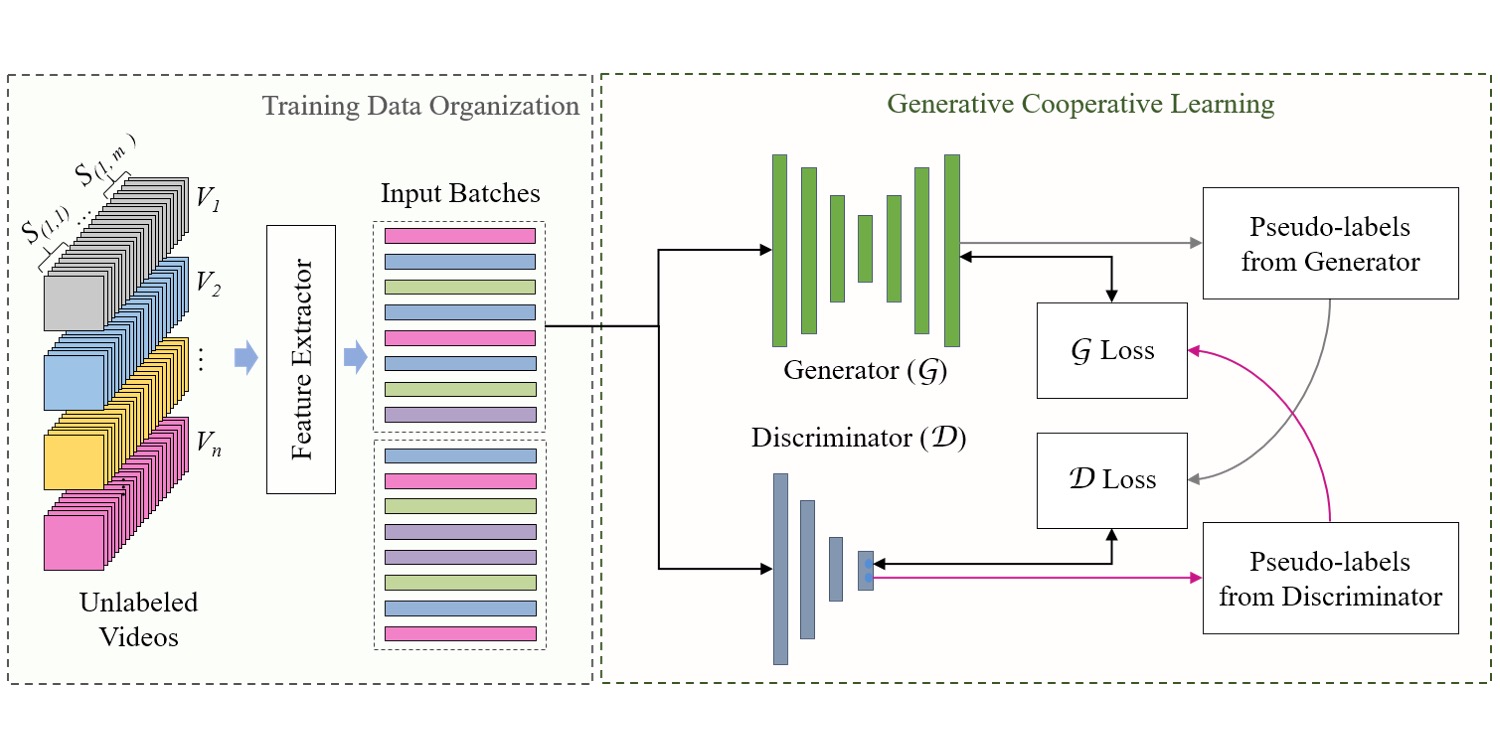 | Generative Cooperative Learning for Unsupervised Video Anomaly Detection |
| M. Zaigham Zaheer, Arif Mahmood, M. Haris Khan, Mattia Segu, Fisher Yu, Seung-Ik Lee | |
| Conference on Computer Vision and Pattern Recognition (CVPR), 2022 | |
| Video anomaly detection is well investigated in weakly supervised and one-class classification (OCC) settings. However, unsupervised video anomaly detection is quite sparse, likely because anomalies are less frequent in occurrence and usually not well-defined, which when coupled with the absence of ground truth supervision, could adversely affect the convergence of learning algorithms. This problem is challenging yet rewarding as it can completely eradicate the costs of obtaining laborious annotations and enable such systems to be deployed without human intervention. To this end, we propose a novel unsupervised Generative Cooperative Learning (GCL) approach for video anomaly detection that exploits the low frequency of anomalies towards building a cross-supervision between a generator and a discriminator. In essence, both networks get trained in a cooperative fashion, thereby facilitating the overall convergence. We conduct extensive experiments on two large-scale video anomaly detection datasets, UCF crime and ShanghaiTech. Consistent improvement over the existing state-of-the-art unsupervised and OCC methods corroborate the effectiveness of our approach. | |
| [arXiv] [CVPR 2022 Paper] | |
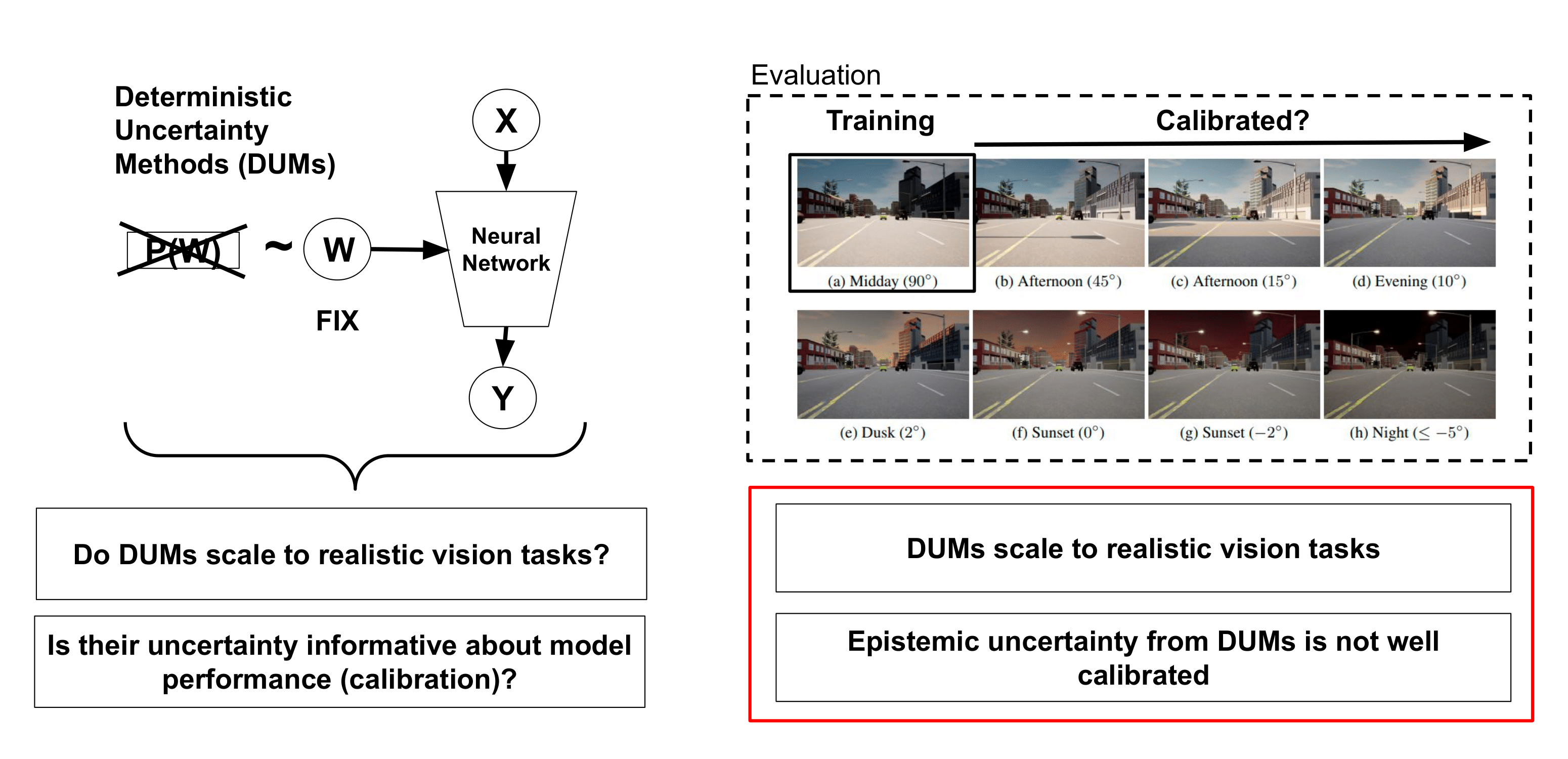 | On the Practicality of Deterministic Epistemic Uncertainty |
| Janis Postels*, Mattia Segu*, Tao Sun, Luc Van Gool, Fisher Yu, Federico Tombari | |
| International Conference on Machine Learning (ICML), 2022 | |
| A set of novel approaches for estimating epistemic uncertainty in deep neural networks with a single forward pass has recently emerged as a valid alternative to Bayesian Neural Networks. On the premise of informative representations, these deterministic uncertainty methods (DUMs) achieve strong performance on detecting out-of-distribution (OOD) data while adding negligible computational costs at inference time. However, it remains unclear whether DUMs are well calibrated and can seamlessly scale to real-world applications - both prerequisites for their practical deployment. To this end, we first provide a taxonomy of DUMs, and evaluate their calibration under continuous distributional shifts. Then, we extend them to semantic segmentation. We find that, while DUMs scale to realistic vision tasks and perform well on OOD detection, the practicality of current methods is undermined by poor calibration under distributional shifts. | |
| [arXiv] [ICML 2022 Paper] [Code] | |
 | A general framework for uncertainty estimation in deep learning |
| Antonio Loquercio*,Mattia Segu*, Davide Scaramuzza | |
| IEEE Robotics and Automation Letters (RA-L), 2020 | |
| Neural networks predictions are unreliable when the input sample is out of the training distribution or corrupted by noise. Being able to detect such failures automatically is fundamental to integrate deep learning algorithms into robotics. Current approaches for uncertainty estimation of neural networks require changes to the network and optimization process, typically ignore prior knowledge about the data, and tend to make over-simplifying assumptions which underestimate uncertainty. To address these limitations, we propose a novel framework for uncertainty estimation. Based on Bayesian belief networks and Monte-Carlo sampling, our framework not only fully models the different sources of prediction uncertainty, but also incorporates prior data information, e.g. sensor noise. We show theoretically that this gives us the ability to capture uncertainty better than existing methods. In addition, our framework has several desirable properties: (i) it is agnostic to the network architecture and task; (ii) it does not require changes in the optimization process; (iii) it can be applied to already trained architectures. We thoroughly validate the proposed framework through extensive experiments on both computer vision and control tasks, where we outperform previous methods by up to 23% in accuracy. | |
| [arXiv] [RA-L 2020 Paper] [Code] | |
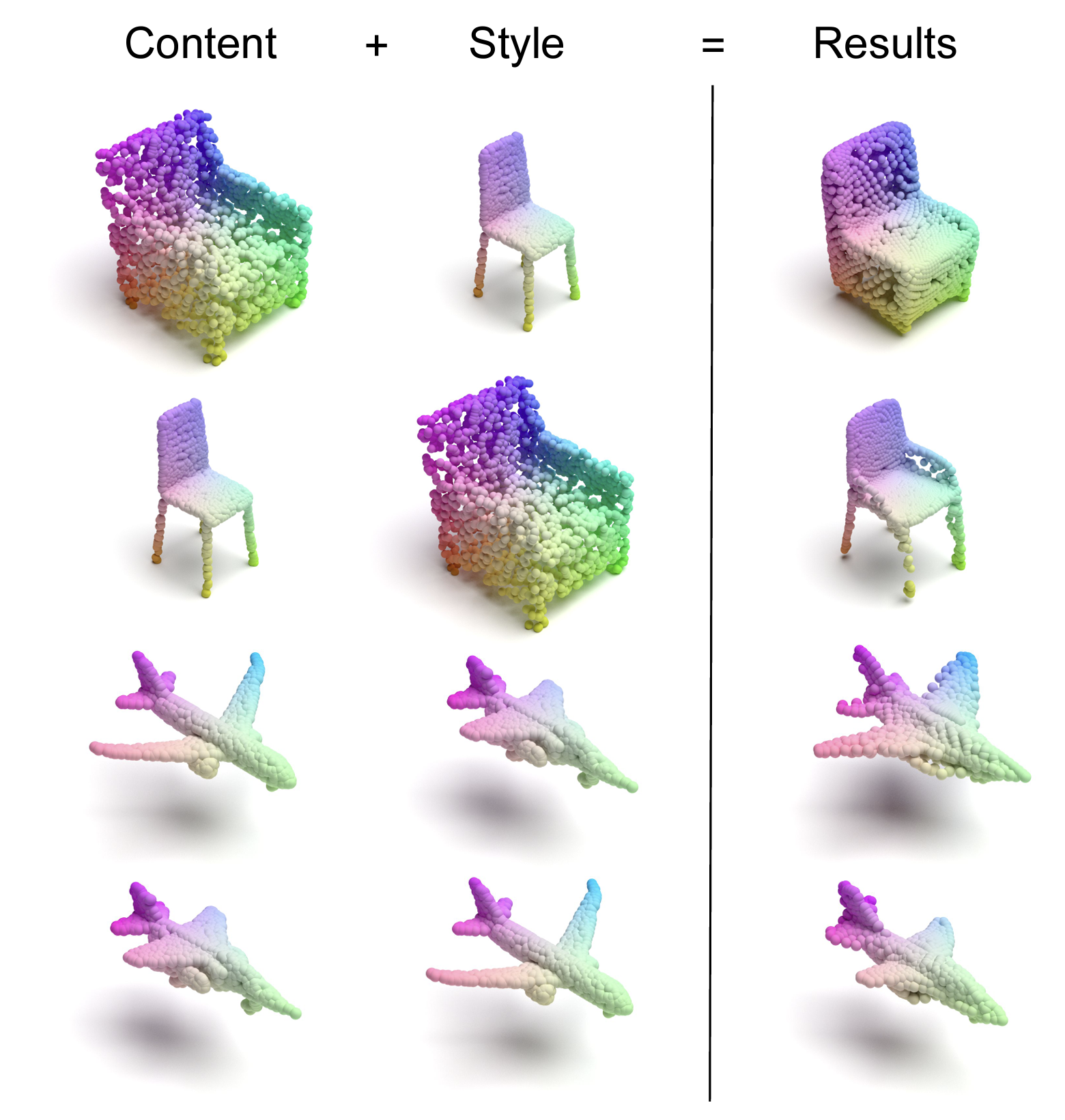 | 3DSNet: Unsupervised Shape-to-Shape 3D Style Transfer |
| Mattia Segu, Margarita Grinvald, Roland Siegwart, Federico Tombari | |
| Pre-Print, 2020 | |
| Transferring the style from one image onto another is a popular and widely studied task in computer vision. Yet, style transfer in the 3D setting remains a largely unexplored problem. To our knowledge, we propose the first learning-based approach for style transfer between 3D objects based on disentangled content and style representations. The proposed method can synthesize new 3D shapes both in the form of point clouds and meshes, combining the content and style of a source and target 3D model to generate a novel shape that resembles in style the target while retaining the source content. Furthermore, we extend our technique to implicitly learn the multimodal style distribution of the chosen domains. By sampling style codes from the learned distributions, we increase the variety of styles that our model can confer to an input shape. Experimental results validate the effectiveness of the proposed 3D style transfer method on a number of benchmarks. | |
| [arXiv] [Paper] [Code] | |